
Apache Pig: High-Level Data Flow Platform
Apache Pig enables people to focus more on analyzing bulk data sets and to spend less time writing Map-Reduce programs.


Introduction
Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turn enables them to handle very large data sets.
Programs must be converted into a succession of Map and Reduce stages in a MapReduce architecture, and data analysts are not conversant with this programming approach. So, on top of Hadoop, an abstraction named Pig was constructed to bridge the gap. Thanks to Apache Pig, people can spend more time evaluating large data sets and less time implementing MapReduce applications.
Internally, Pig scripts are translated to Map Reduce tasks, which are then run on HDFS data. The pig can run its code on Apache Tez or Apache Spark, among other things.
Apache Pig can process data of all types: whether structured,semi-structured, or unstructured, and store the results in the Hadoop Data File System. Every operation that can be accomplished with PIG can also be accomplished with Java in MapReduce.
Origin of Apache Pig:
Yahoo’s researchers built Apache Pig earlier in 2006. The pig was created with the primary goal of executing MapReduce operations on huge datasets at the time. It was moved to the Apache Software Foundation (ASF) in 2007, making it an open-source project. Pig’s first version (0.1) was released in 2008.
Need for Apache Pig:
Programmers who aren’t fluent in Java have traditionally struggled with Hadoop, particularly when conducting MapReduce operations. For all of these programmers, Apache Pig is a godsend tool.
Pig Latin allows programmers to quickly run MapReduce jobs without entering sophisticated Java code.
Apache Pig employs a multi-query method to reduce code length. For example, an operation that would take 200 lines of code (LoC) in Java can be completed in as little as 10 lines of code (LoC) in Apache Pig. Finally, Apache Pig cuts development time by about 16 times.
Pig Latin is a SQL-like language that is simple to learn if you are already familiar with SQL.
Many built-in operators in Apache Pig provide data operations such as joins, filters, and ordering. It also includes nested data types like tuples, bags, and maps, which are unavailable in MapReduce.
Features
There are many features of Apache Pig. Let us have a look:
It includes a wide range of operators for executing various tasks, such as filters, joins, and sorting.
It is simple to learn, read, and write.
It is flexible, allowing you to create your functions and processes.
It makes joining operations simple.
Splits in the pipeline are possible with Apache Pig.
The data structure is more complex, hierarchical, and multivalued.
The pig can handle both structured and unstructured data processing.
If a programmer desires to build custom functions that are currently unavailable, Apache Pig allows them to write User Defined Functions in any language. The Pig script then includes this UDF, and Apache Pig gains extensibility as a result of this.
The pig can deal with schema inconsistencies.
Apache Pig can extract data, run actions on it, and then dump it back into HDFS in the desired format. We may utilize it for ETL (Extract Transform Load) activities.
Components
The Apache Pig components that process the Pig Latin language over various levels are as follows:
Parser: The parser receives a user-supplied program and conducts a syntax and type check. This procedure produces a DAG, including Pig Latin sentences and logical operators.
Optimizer: This step sends the DAG to a logical optimizer for logical optimization.
Compiler: This is the stage at which the optimal logical plan is turned into MapReduce tasks. This is the stage at which the optimal logical strategy is turned into MapReduce tasks.
Execution Engine: The MapReduce jobs are sent to Hadoop for execution in this final stage. On completion, the user receives the desired data.
Pig Architecture
Pig’s architecture is divided into two parts:
Pig Latin, which is a language
A runtime environment for running PigLatin programs.
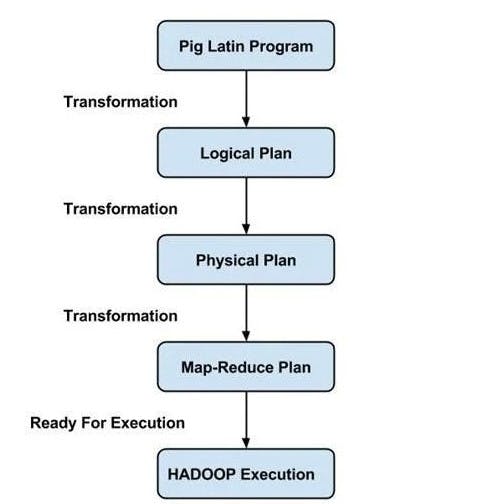
A Pig Latin program is made up of a set of operations or transformations that are executed to input data to generate output. These procedures define a data flow that the Hadoop Pig execution environment converts into an executable form. The outputs of these modifications are a sequence of MapReduce tasks that are hidden from the programmer. Pig in Hadoop, in a sense, lets the programmer concentrate on the data rather than the nature of the execution.
PigLatin is a relatively stiffened language that utilizes common data processing phrases like Join, Group, and Filter.
Pig has two execution modes in Hadoop:
Local mode: The Hadoop Pig language operates in a single JVM and uses the local file system in this mode. This mode is only useful for analyzing tiny datasets in Hadoop using Pig.
Map Reduce mode: In this mode, Pig Latin queries are converted into MapReduce jobs and executed on a Hadoop cluster (cluster may be pseudo or fully distributed). Pig can execute on huge datasets in MapReduce mode with a fully distributed cluster.
Difference Between Pig and MapReduce
There are certain differences between Apache Pig and Map Reduce, let us analyze them.
PIG | MapReduce |
It is a scripting language. | Map Reduce is a properly compiled programming language. |
The level of abstraction is high. | The level of abstraction is low. |
When compared to MapReduce, it has fewer lines of code. | It has more lines of code. |
Apache Pig requires less work. | MapReduce will necessitate more development work. |
Applications
There are many uses and applications of Apache Pig, let us see what they are.
Pig Scripting is used to explore huge databases.
Provides support for ad-hoc searches over huge data sources.
Processing methods for massive data collections are prototyping.
Processing time-sensitive data loads are required.
Search logs and web crawls are used to acquire vast volumes of data.
When analytical insights are required, sampling is used.
Data Model in Pig
There are four data models in Apache Pig, they are:
Atom: The basic data types in Pig Latin are atomic, also known as scalar data types, which are utilized in all kinds such as string, float, int, double, long, char[], and byte[]. Primitive data types are another name for atomic data types. In a field (column), each cell value is an atomic data type.
Tuple: A tuple is an ordered collection of fields. The ‘()’ symbol is used to indicate the tuple. The indices of the fields can be used to access fields in each tuple.
Bag: It is a collection of tuples of potentially varying structures and can contain duplicates. The bag is similar to the table in RDBMS. In contrast to RDBMS tables, Bag does not require that every tuple include the same amount of fields, or that all columns be in the same place or be of the same type.
Map: It is an associative array.
Conclusion
Users can write their functions for special-purpose processing, for tasks like reading and writing data, in Apache Pig. It can analyze different types of data, both structured and unstructured, and supports many data types. It supports user-defined functions, allowing users to write functions in other programming languages like Java.
We had a broad look at Apache Pig, so summarize what we discussed so far:
Pig is a high-level data flow scripting language in Hadoop that consists of two main components: a runtime engine and a Pig Latin language.
Pig has two modes of execution: local and MapReduce.
Before we set up the environment for Pig Latin, make sure that all Hadoop services are up and running, that Pig is fully installed and configured, and that all relevant datasets are uploaded to HDFS.
Non-programmers will find it difficult to write complicated Java programs for map-reduce. This is made simple by Pig, and the queries are transformed to MapReduce in Pig.